《基于改进协同过滤与多目标优化的健康饮食推荐系统设计与实现》实施进度
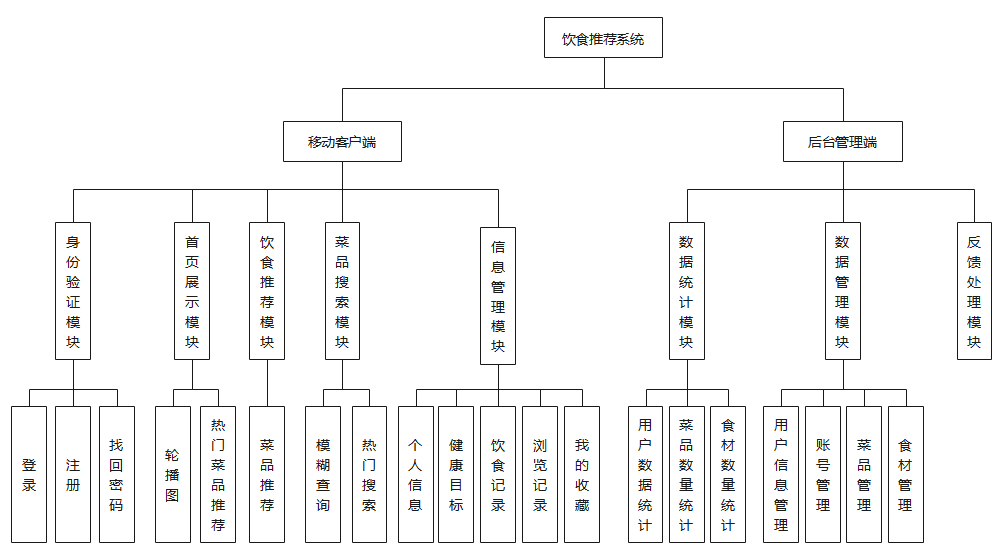
一、功能模块图
二、系统总体架构
系统基于若依框架分层架构设计,从下到上分为**数据服务层、业务逻辑层、交互展现层,支撑移动端(普通用户)与后台管理端(管理员)的核心功能**
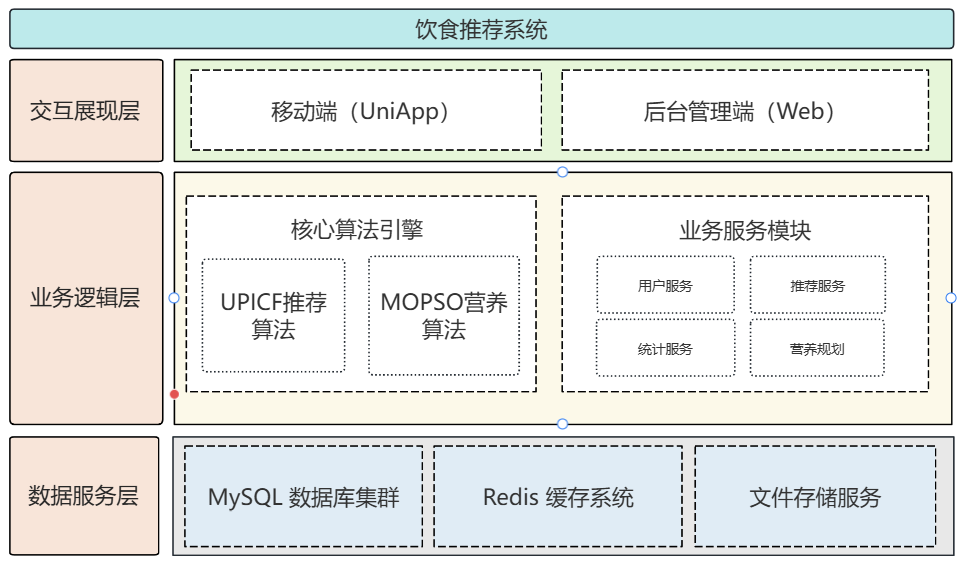
具体架构职责如下:
| 架构层级 | 核心职责 | 关键实现 |
|---|---|---|
| 数据服务层 | 数据存储与交互支撑 | 调用自定义接口与 MySQL 数据库交互,处理用户、菜品、食材、营养参考值等数据的增删改查,为上层提供基础数据支撑 |
| 业务逻辑层 | 功能逻辑处理与算法计算 | 解析用户请求,结合****改进协同过滤(UPICF)、**多目标粒子群(MOPSO)**算法处理数据,以 JSON 格式返回结果 |
| 交互展现层 | 用户与系统的交互窗口 | 移动端(Android APP)提供用户操作界面;后台管理端(Web 浏览器)提供管理员数据管理界面 |
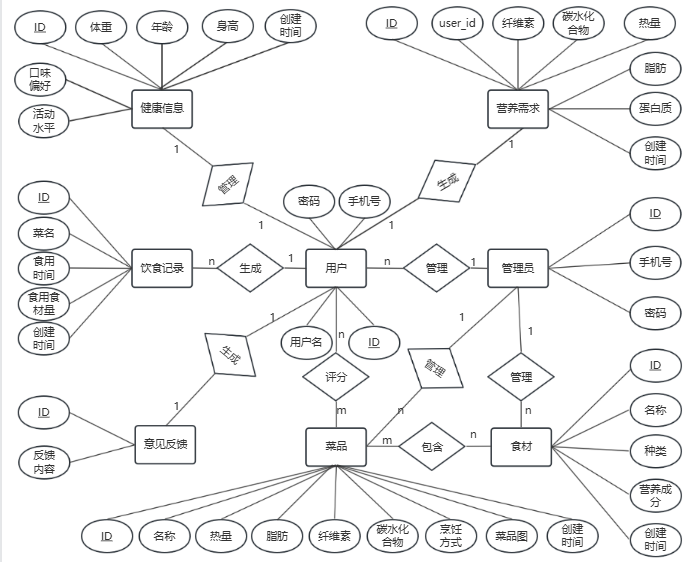
三、 数据库表
核心 ER 图
基于若依的数据表
| 序号 | 表名 | 作为 |
|---|---|---|
| 1 | gen_table | 代码生成业务表 |
| 2 | gen_table_column | 代码生成业务表字段 |
| 3 | qrtz_blob_triggers | Blob 类型的触发器表 |
| 4 | qrtz_calendars | 日历信息表 |
| 5 | qrtz_cron_triggers | Cron 类型的触发器表 |
| 6 | qrtz_fired_triggers | 已触发的触发器表 |
| 7 | qrtz_job_details | 任务详细信息表 |
| 8 | qrtz_locks | 存储的悲观锁信息表 |
| 9 | qrtz_paused_trigger_grps | 暂停的触发器表 |
| 10 | qrtz_scheduler_state | 调度器状态表 |
| 11 | qrtz_simple_triggers | 简单触发器的信息表 |
| 12 | qrtz_simprop_triggers | 同步机制的行锁表 |
| 13 | qrtz_triggers | 触发器详细信息表 |
| 14 | sys_config | 参数配置表 |
| 15 | sys_dept | 部门表 |
| 16 | sys_dict_data | 字典数据表 |
| 17 | sys_dict_type | 字典类型表 |
| 18 | sys_job | 定时任务调度表 |
| 19 | sys_job_log | 定时任务调度日志表 |
| 20 | sys_logininfor | 系统访问记录 |
| 21 | sys_menu | 菜单权限表 |
| 22 | sys_notice | 通知公告表 |
| 23 | sys_oper_log | 操作日志记录 |
| 24 | sys_post | 岗位信息表 |
| 25 | sys_role | 角色信息表 |
| 26 | sys_role_dept | 角色和部门关联表 |
| 27 | sys_role_menu | 角色和菜单关联表 |
| 28 | sys_user | 用户信息表 |
| 29 | sys_user_post | 用户与岗位关联表 |
| 30 | sys_user_role | 用户和角色关联表 |
新增数据表
一、用户健康信息表(<span class="ne-text">user_health_info</span>)支撑 UPICF
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
| id | bigint | 20 | 否 | 是 | 主键 ID | - |
| user_id | bigint | 20 | 否 | 否 | 用户 ID(关联系统用户) | sys_user(id) |
| age | int | 3 | 否 | 否 | 用户年龄(如 18-60) | - |
| height | int | 3 | 否 | 否 | 身高(cm,如 170) | - |
| weight | int | 3 | 否 | 否 | 体重(kg,如 70) | - |
| occupation | varchar | 50 | 是 | 否 | 职业(如“办公室职员”“建筑工人”) | - |
| activity_level | tinyint | 1 | 否 | 否 | 体力活动水平:1=轻(办公室职员)、2=中(教师)、3=重(建筑工人) | - |
| flavor_preference | varchar | 50 | 是 | 否 | 口味偏好(如“辣”“甜”“鲜”) | - |
二、菜品信息表(<span class="ne-text">dish_info</span>)支撑 UPICF、MOPSO
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
| id | bigint | 20 | 否 | 是 | 主键 ID | - |
| dish_name | varchar | 100 | 否 | 否 | 菜品名称(如“木耳炒肉”) | - |
| cuisine | varchar | 50 | 是 | 否 | 菜系(如“川菜”“粤菜”) | - |
| taste | varchar | 50 | 是 | 否 | 口味(枚举:辣/甜/鲜/咸/清淡) | - |
<span class="ne-text">cooking_method</span> |
varchar | 20 | 否 | 否 | 烹饪方式(枚举:煎/炒/煮/蒸/烤) | 考虑中 |
| calories | decimal | 6,2 | 是 | 否 | 热量(千卡/100 克) | |
| protein | decimal | 5,2 | 是 | 否 | 蛋白质(克/100 克) | |
| fat | decimal | 5,2 | 是 | 否 | 脂肪(克/100 克) | |
| carbohydrate | decimal | 5,2 | 是 | 否 | 碳水化合物(克/100 克) | |
<span class="ne-text">fiber</span> |
decimal | 5,2 | 是 | 否 | 纤维素(克/100 克,如 3.50) | |
| img_url | varchar | 255 | 是 | 否 | 菜品图片 URL | - |
| create_by | varchar | 64 | 否 | 否 | 创建人(管理员 ID) | <span class="ne-text">sys_user</span>(username) |
| create_time | datetime | - | 否 | 否 | 创建时间 | - |
| update_by | varchar | 64 | 是 | 否 | 更新人 | <span class="ne-text">sys_user</span>(username) |
| update_time | datetime | - | 是 | 否 | 更新时间 | - |
三、食材信息表(<span class="ne-text">ingredient_info</span>)支撑 MOPSO
支撑 MOPSO 营养规划
用途:存储食材营养数据,支撑营养规划算法(MOPSO),数据源自《中国食物成分表》。
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
| id | bigint | 20 | 否 | 是 | 主键 ID | - |
| igd_name | varchar | 100 | 否 | 否 | 食材名称(如“黑木耳”“猪肉”) | - |
| igd_category | varchar | 50 | 是 | 否 | 食材类别(如“蔬菜类”“肉类”) | - |
| calories | decimal | 6,2 | 是 | 否 | 热量(千卡/100 克) | - |
| protein | decimal | 5,2 | 是 | 否 | 蛋白质(克/100 克) | - |
| fat | decimal | 5,2 | 是 | 否 | 脂肪(克/100 克) | - |
| carbohydrate | decimal | 5,2 | 是 | 否 | 碳水化合物(克/100 克) | - |
<span class="ne-text">fiber</span> |
decimal | 5,2 | 是 | 否 | 纤维素(克/100 克) | |
| create_time | datetime | - | 否 | 否 | 创建时间 | - |
| update_time | datetime | - | 是 | 否 | 更新时间 | - |
四、菜品-食材关联表(<span class="ne-text">dish_ingredient_rel</span>)支撑 MOPSO
用途:关联菜品与食材,记录食材在菜品中的用量比例(多对多关系)。
菜品-食材关联表(<span class="ne-text">dish_ingredient</span>):支撑 MOPSO 营养计算
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
<span class="ne-text">id</span> |
bigint | 20 | 否 | 是 | 主键 ID | - |
<span class="ne-text">dish_id</span> |
bigint | 20 | 否 | 否 | 菜品 ID(关联<span class="ne-text">dish_info.id</span>) |
<span class="ne-text">dish_info(id)</span> |
<span class="ne-text">igd_id</span> |
bigint | 20 | 否 | 否 | 食材 ID(关联<span class="ne-text">ingredient_info.id</span>) |
<span class="ne-text">ingredient_info(id)</span> |
<span class="ne-text">quantity</span> |
decimal | 6,2 | 否 | 否 | 用量(克,如 100.00) | - |
<span class="ne-text">unit</span> |
varchar | 10 | 是 | 否 | 单位(如“克”“个”) | - |
<span class="ne-text">create_time</span> |
datetime | - | 否 | 否 | 创建时间 | - |
五、菜品评分表(<span class="ne-text">dish_rating</span>)支撑 UPICF
用途:存储用户对菜品的评分,支撑改进协同过滤算法(UPICF)的偏好预测。
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
| id | bigint | 20 | 否 | 是 | 主键 ID | - |
| user_id | bigint | 20 | 否 | 否 | 用户 ID | <span class="ne-text">sys_user</span>(id) |
| dish_id | bigint | 20 | 否 | 否 | 菜品 ID | <span class="ne-text">dish_info</span>(id) |
| rating | tinyint | 1 | 否 | 否 | 评分值(1~5 分) | - |
| rating_time | datetime | - | 否 | 否 | 评分时间(用于时间权重计算) | - |
| unique key | (user_id,dish_id) | - | - | - | 唯一约束(同一用户对同一菜品仅能评一次) | - |
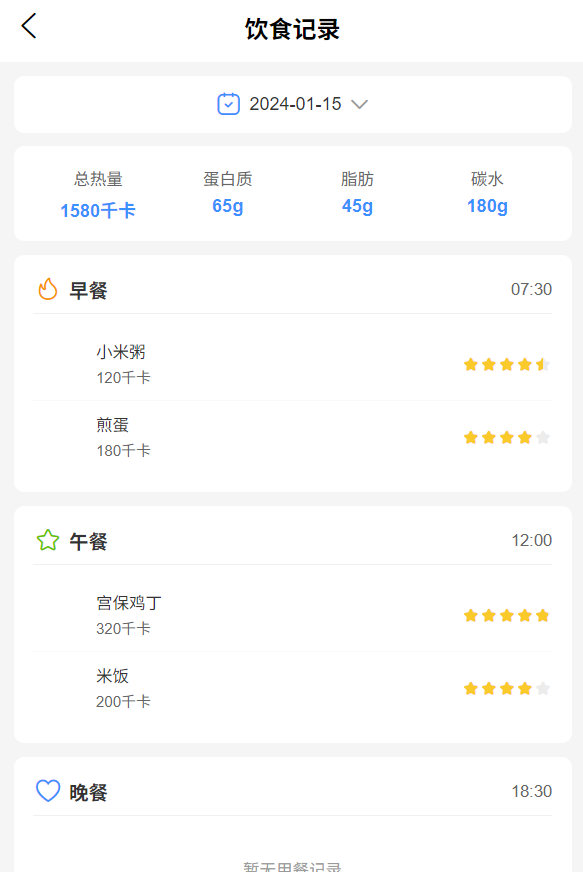
六、饮食记录表(<span class="ne-text">food_record</span>)支撑 UPICF
用途**:**记录用户选择的菜品及食用量,用于推荐时排除“近 3 日已食用菜品”。
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
| id | bigint | 20 | 否 | 是 | 主键 ID | - |
| user_id | bigint | 20 | 否 | 否 | 用户 ID | <span class="ne-text">sys_user</span>(id) |
| dish_id | bigint | 20 | 否 | 否 | 菜品 ID | <span class="ne-text">dish_info</span>(id) |
| eat_time | datetime | - | 否 | 否 | 食用时间 | - |
| ingredient_amount | text | - | 是 | 否 | 食材食用量(JSON 格式,如{“黑木耳”:79.1,”猪肉”:50}) | - |
| create_time | datetime | - | 否 | 否 | 记录创建时间 | - |
七、意见反馈表(<span class="ne-text">opinion_feedback</span>)支撑 UPICF
用途:存储用户反馈信息,支撑管理员后台的反馈处理功能。
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
| id | bigint | 20 | 否 | 是 | 主键 ID | - |
| user_id | bigint | 20 | 否 | 否 | 反馈用户 ID | <span class="ne-text">sys_user</span>(id) |
| feedback_type | varchar | 50 | 否 | 否 | 反馈类型(如“功能 bug”“建议”) | - |
| content | text | - | 否 | 否 | 反馈内容(5~200 字) | - |
| handle_status | tinyint | 1 | 否 | 否 | 处理状态:0=未处理、1=已处理 | - |
| handle_remark | text | - | 是 | 否 | 处理备注(管理员填写) | - |
| handle_by | varchar | 64 | 是 | 否 | 处理人 | <span class="ne-text">sys_user</span>(username) |
| submit_time | datetime | - | 否 | 否 | 提交时间 | - |
| handle_time | datetime | - | 是 | 否 | 处理时间 | - |
八、用户-菜品交互表(<span class="ne-text">user_dish_interaction</span>):支撑 UPICF 核心
用途:存储用户对菜品的**行为数据(如评分、收藏),是 UPICF 计算用户偏好与菜品相似性的基础。 关键说明:<span class="ne-text">interaction_type</span>(交互类型)用枚举值(评分/收藏/点击),rating(评分)仅当交互类型为“评分”时有效,**<span class="ne-text">count</span>(次数)仅当交互类型为“点击”时有效。
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
<span class="ne-text">id</span> |
bigint | 20 | 否 | 是 | 主键 ID | - |
<span class="ne-text">user_id</span> |
bigint | 20 | 否 | 否 | 用户 ID(关联<span class="ne-text">user_info.id</span>) |
<span class="ne-text">user_info(id)</span> |
<span class="ne-text">dish_id</span> |
bigint | 20 | 否 | 否 | 菜品 ID(关联<span class="ne-text">dish_info.id</span>) |
<span class="ne-text">dish_info(id)</span> |
<span class="ne-text">interaction_type</span> |
varchar | 20 | 否 | 否 | 交互类型(枚举:评分/收藏/购买/点击) | - |
| rating | tinyint | 1 | 是 | 否 | 评分(1-5 分,仅评分时有效) | - |
<span class="ne-text">count</span> |
int | 10 | 是 | 否 | 次数(仅点击时有效) | - |
<span class="ne-text">create_time</span> |
datetime | - | 否 | 否 | 创建时间 | - |
九. 用户营养需求表(<span class="ne-text">user_nutrition_goal</span>):支撑 MOPSO 目标函数
用途:存储用户**每日营养目标(如热量 1500 千卡、蛋白质 100 克),是 MOPSO多目标优化的输入(如最小化热量、最大化蛋白质)。 关键说明:<span class="ne-text">calorie_goal</span>(热量目标)用千卡,<span class="ne-text">protein_goal</span>(蛋白质目标)用克****,统一单位确保计算准确性。**
| 字段名 | 数据类型 | 长度 | 是否为空 | 主键 | 说明 | 关联表 |
|---|---|---|---|---|---|---|
<span class="ne-text">id</span> |
bigint | 20 | 否 | 是 | 主键 ID | - |
<span class="ne-text">user_id</span> |
bigint | 20 | 否 | 否 | 用户 ID(关联<span class="ne-text">user_info.id</span>) |
<span class="ne-text">user_info(id)</span> |
<span class="ne-text">calorie_goal</span> |
decimal | 6,2 | 否 | 否 | 热量目标(千卡/天,如 1500.00) | - |
<span class="ne-text">protein_goal</span> |
decimal | 5,2 | 否 | 否 | 蛋白质目标(克/天,如 100.00) | - |
<span class="ne-text">fat_goal</span> |
decimal | 5,2 | 否 | 否 | 脂肪目标(克/天,如 50.00) | - |
<span class="ne-text">carbohydrate_goal</span> |
decimal | 5,2 | 否 | 否 | 碳水化合物目标(克/天,如 200.00) | - |
<span class="ne-text">fiber_goal</span> |
decimal | 5,2 | 否 | 否 | 纤维素目标(克/天,如 25.00) | - |
<span class="ne-text">create_time</span> |
datetime | - | 否 | 否 | 创建时间 | - |
四、模型数据来源
用户数据来源
**发放调查问卷 40 份 ,回收 38 份,有效 33 份;**附件 1
调查问卷
1 | 第一部分:基础信息与健康画像 |
问卷分析
性别分布
| 性别 | 数量 |
|---|---|
| 男 | 17 |
| 女 | 16 |
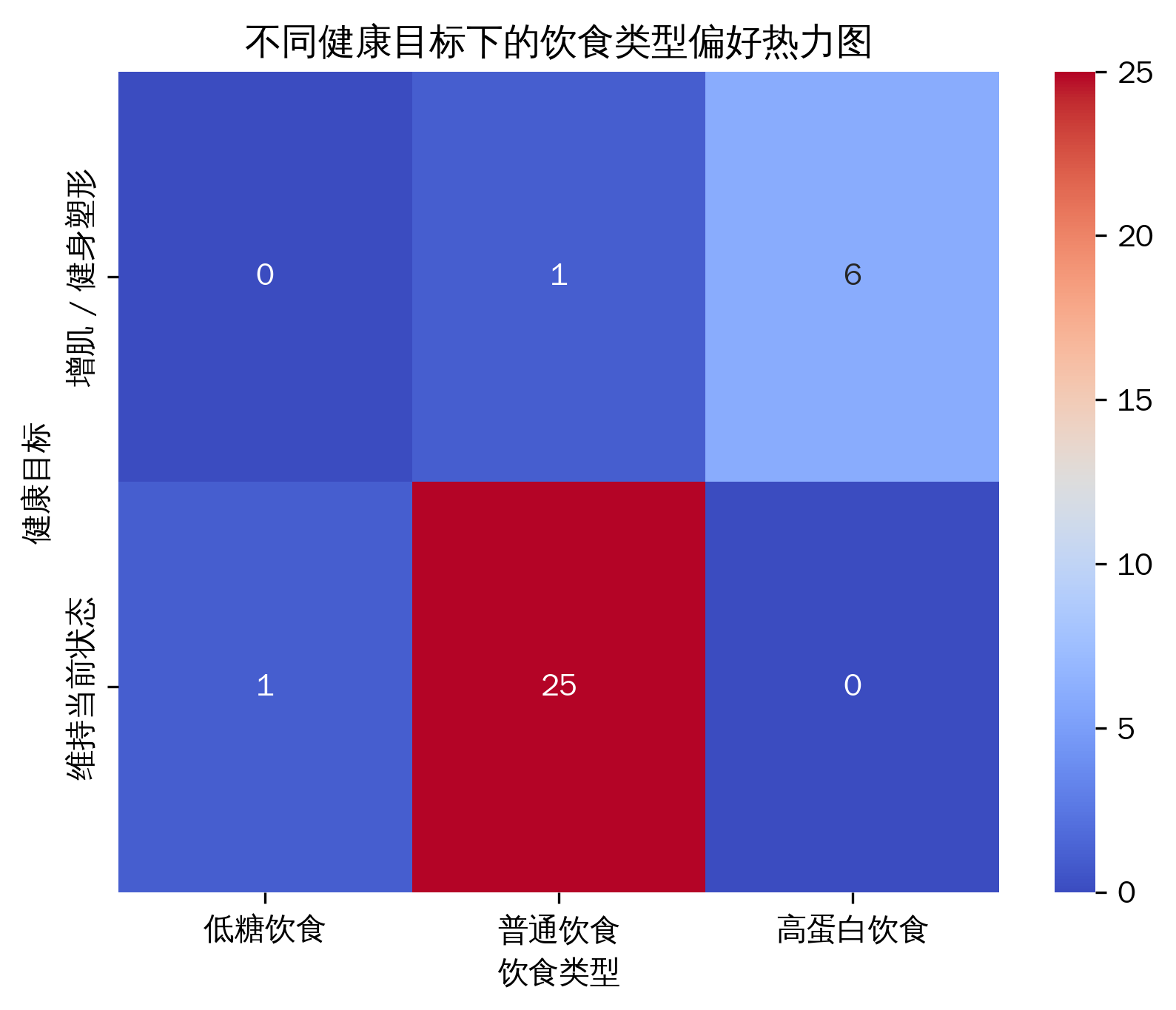
不同健康目标下的饮食类型偏好热力图
菜品数据来源
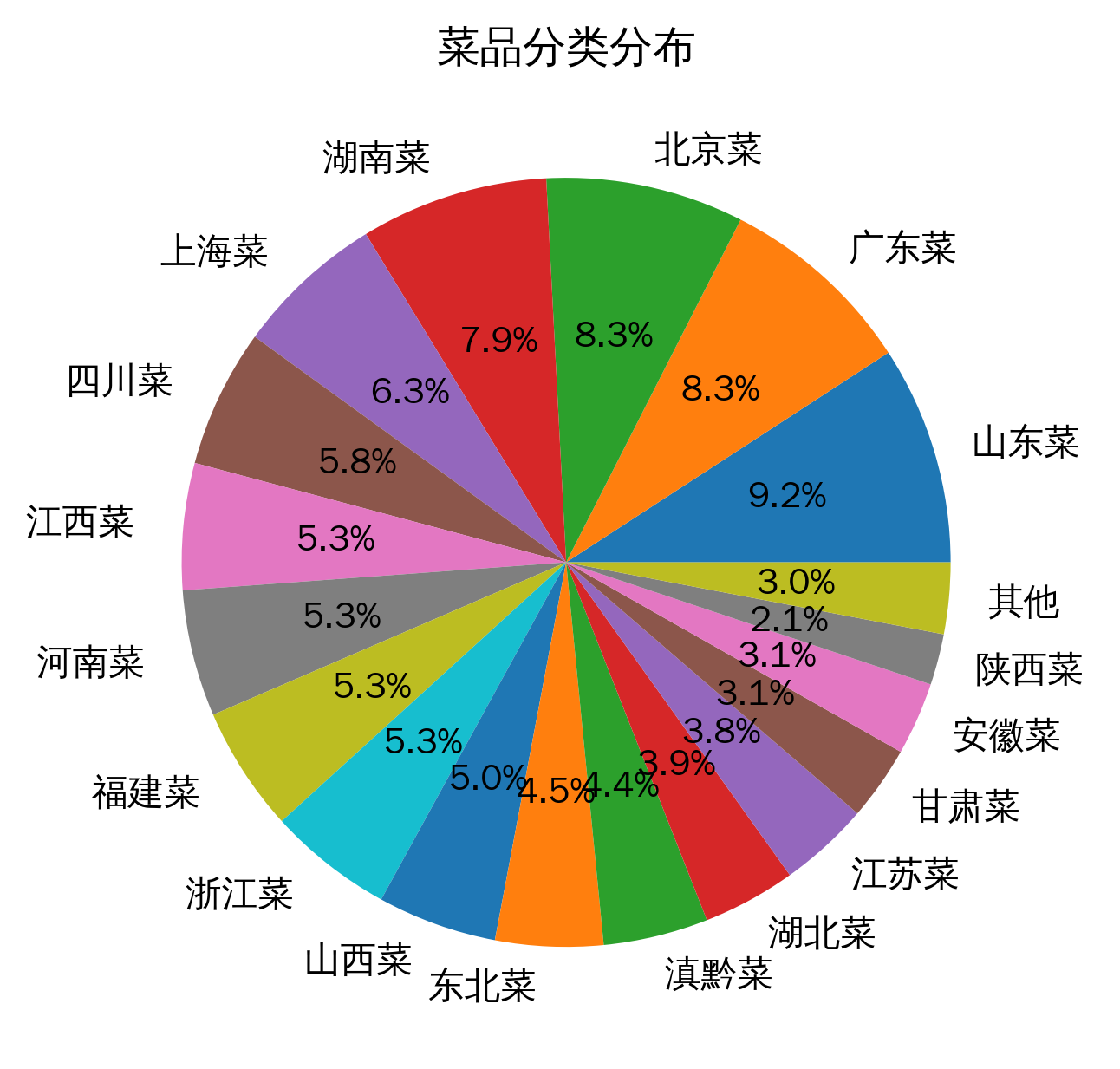
来自爬取薄荷健康-1635 道 涵盖菜品分布的菜系有山东菜、广东菜、北京菜、湖南菜、上海菜、四川菜、江西菜、河南菜、福建菜、浙江菜、山西菜、东北菜、滇黔菜、湖北菜、江苏菜、甘肃菜、安徽菜、陕西菜、台湾菜、新疆菜、海南菜、广西菜、天津菜、青海菜、宁夏菜。附件 2
菜品分类分布
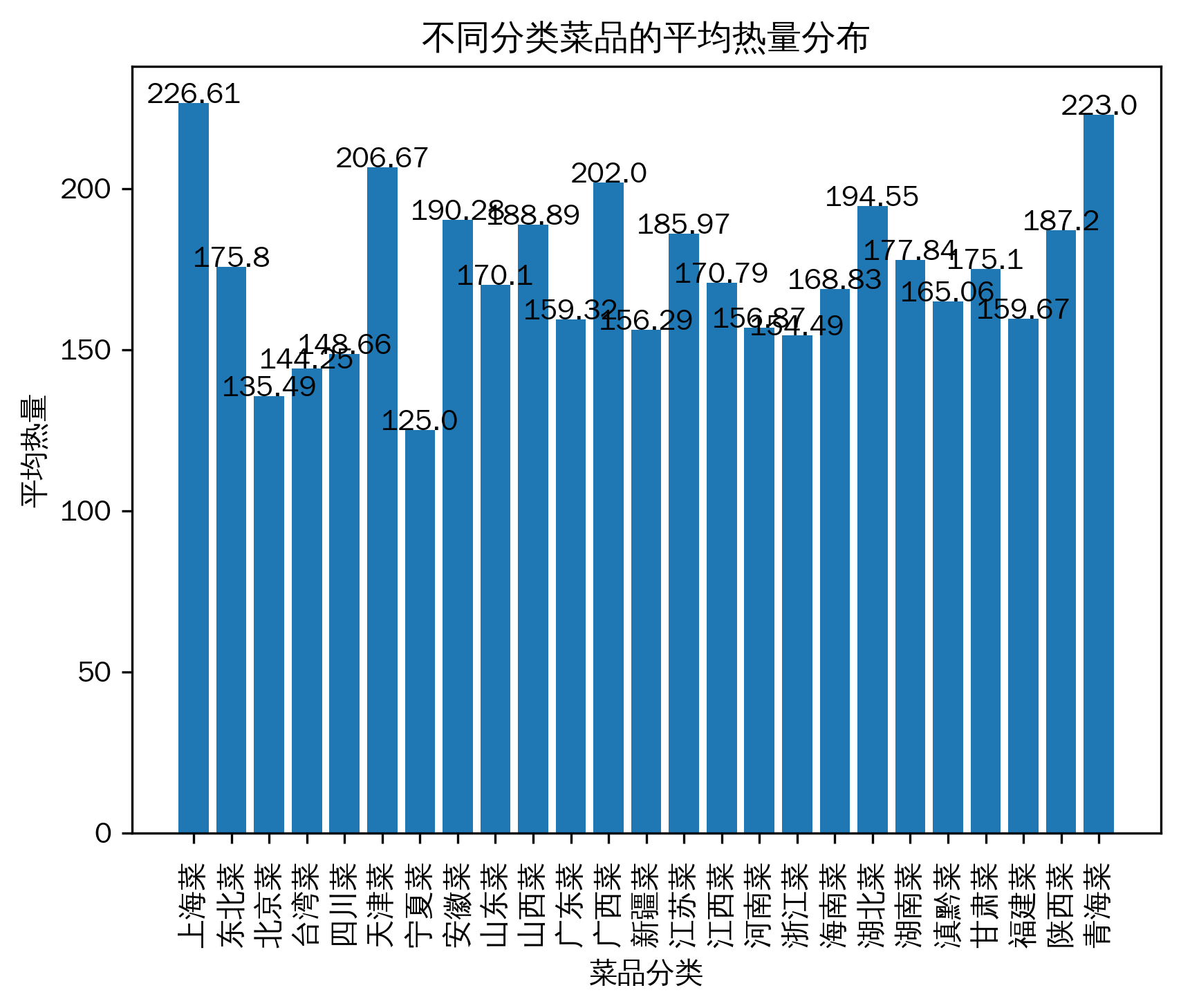
菜品热量分布
五、数据处理
针对 33 份用户数据扩展到 960 名用户,扩展倍数为 30 倍。通过:1.**数值型增强、2.类别型增强 、3.特征插值增强、4.模式增强 、5.语义增强,增强后用户数据 **附件 3
增强方法
1. 数值型增强 (Numerical Augmentation)
原理:对用户的数值型偏好特征添加高斯噪声进行轻微扰动,生成相似但略有差异的用户数据。
实现方式:
- 对每个原始用户生成 5 个变体
- 对数值特征(如口味偏好、营养关注等)添加符合正态分布的噪声
- 噪声范围控制在 ±0.5 到 ±0.8 之间
- 保证扰动后的值在 1-5 的有效范围内
特征范围:
- 口味偏好:spicy_preference, sweet_preference, salty_preference, sour_preference, greasy_preference, light_preference
- 营养关注:calorie_focus, protein_focus, fat_focus, carb_focus, vitamin_focus, fiber_focus
2. 类别型增强 (Categorical Augmentation)
原理:基于用户群体特征(性别和 BMI 分类)进行分组,同组用户之间交换部分特征,生成新的用户组合。
实现方式:
- 按照性别和 BMI 类别对用户进行分组
- 在每组内部随机选择两个用户进行特征交换
- 交换特征包括:口味偏好和饮食规律性特征
- 每组最多生成 3 个组合变体
3. 特征插值增强 (Interpolation Augmentation)
原理:采用 SMOTE(Synthetic Minority Oversampling Technique)思想,对相似用户进行线性插值生成中间用户。
实现方式:
- 使用 KNN 算法找到相似用户对
- 对数值特征进行线性插值:
<span class="ne-text">interpolated = user1[col] * alpha + user2[col] * (1 - alpha)</span> - 插值系数 alpha 在 0.3-0.7 之间随机选择
- 每对相似用户生成 2-3 个插值变体
4. 模式增强 (Pattern Augmentation)
原理:识别并过采样少数用户模式,确保所有用户群体在增强数据中得到充分表示。
实现方式:
- 基于健康目标和口味偏好强度识别用户模式
- 对用户数少于 5 个的少数模式进行过采样
- 为每个少数模式用户生成 3-5 个轻微扰动变体
- 扰动范围限制在 ±1 以内
5. 语义增强 (Semantic Augmentation)
原理:结合地域饮食文化和健康目标模板,生成具有特定语义特征的用户数据。
实现方式:
- 基于 6 个中国主要地域的饮食偏好模板(四川、广东、江苏、湖南、浙江、山东)
- 为每个原始用户随机选择 2-3 个地域
- 将用户原始偏好与地域特征进行混合:
<span class="ne-text">blended_value = (original_value + template_value) / 2</span> - 结合用户主要健康目标模板进一步调整相关特征
数据后处理
去重策略
- 基于关键特征(gender, age, bmi, spicy_preference, light_preference)进行去重
- 确保生成的用户数据具有足够的多样性
数量调整
- 若去重后数据不足目标数量,通过随机复制补充
- 若去重后数据超出目标数量,通过随机抽样调整
- 最终确保生成恰好 960 名用户的数据集
地域饮食偏好模板
系统内置了 6 个中国主要地域的饮食偏好模板:
- 四川:偏好辣味、咸味、酸味和油腻食物
- 广东:偏好甜味和清淡食物
- 江苏:偏好甜味和清淡食物,适量咸味
- 湖南:偏好辣味、咸味和酸味
- 浙江:偏好甜味和清淡食物,适量咸味
- 山东:偏好咸味和油腻食物
健康目标模板
系统针对三种主要健康目标设置了特征权重模板:
- 减重目标:重点关注热量、脂肪、碳水化合物和纤维
- 增肌目标:重点关注蛋白质、热量和碳水化合物
- 健康维持:均衡关注热量、蛋白质、纤维和维生素
最终数据附件 4、附件 5、附件 6
六、模型说明
推荐系统架构:
- 第一阶段:协同过滤推荐(UPICF)
- 基于用户行为数据计算用户相似度
- 生成候选菜品推荐列表
- 为每个用户生成个性化评分预测
- 第二阶段:多目标优化(MOPSO)
- 基于用户健康目标和营养需求优化推荐
- 使用粒子群优化算法生成最优餐食组合
- 平衡营养均衡、用户偏好和多样性
整体详细说明流程图
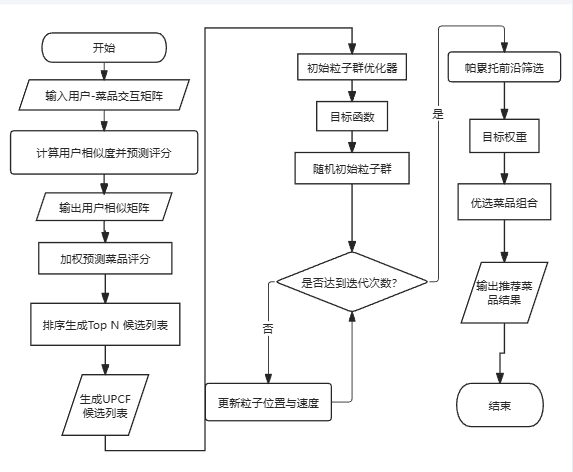
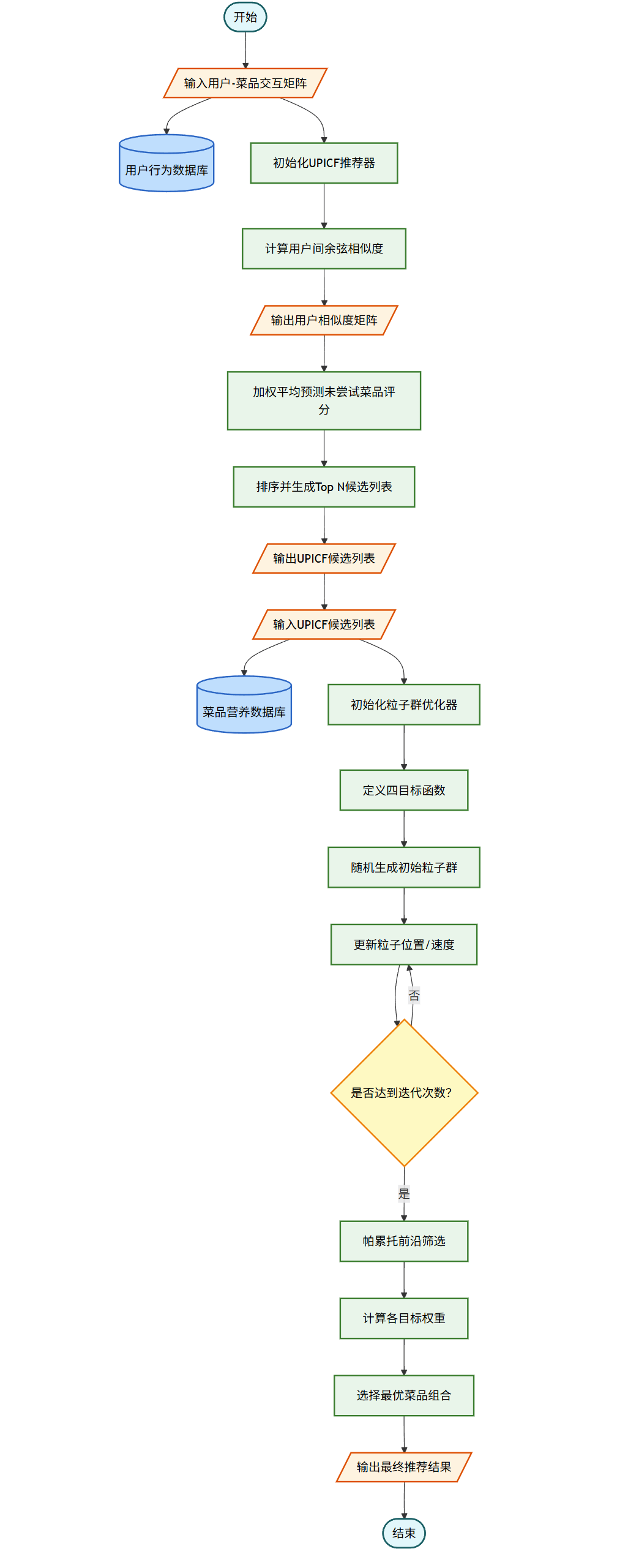
UPICF 协同过滤流程
1.2.1 初始化
- 输入用户-菜品交互矩阵和用户特征数据
- 初始化推荐器实例
1.2.2 相似度计算
- 使用余弦相似度计算用户间相似性
- 构建用户相似度矩阵
1.2.3 评分预测
- 对于每个用户,找到最相似的 K 个用户
- 基于相似用户的评分计算目标用户对未尝试菜品的预测评分
- 使用加权平均方法,权重为用户相似度
1.2.4 推荐生成
- 根据预测评分对菜品进行排序
- 选择评分最高的 N 个菜品作为推荐结果
MOPSO 多目标优化流程
1.3.1 初始化
- 以 UPICF 推荐结果作为输入
- 初始化粒子群优化器,设置粒子数量、迭代次数等参数
- 获取用户特征和菜品特征数据
1.3.2 目标函数定义
包含四个优化目标:
- UPICF 推荐分数:最大化协同过滤推荐的评分
- 营养均衡性:最小化实际摄入与理想营养比例的偏差
- 健康目标匹配度:根据用户健康目标(减重、增肌、维持等)匹配菜品
- 口味偏好匹配度:匹配用户的口味偏好(辣味、甜味、清淡等)
1.3.3 优化过程
- 随机生成初始粒子群,每个粒子代表一种菜品组合方案
- 迭代优化,更新粒子位置和速度
- 计算每个粒子的适应度(目标函数值)
- 跟踪个体最优解和全局最优解
- 使用帕累托前沿选择非支配解
1.3.4 结果选择
- 根据用户特征计算各目标的权重
- 从帕累托最优解中选择加权得分最高的方案
- 输出包含菜品、营养信息的详细推荐结果
七、模型评估
推荐系统评估结果总览
| 评估维度 | 具体指标 | 指标值 | 表现评价 | 核心问题与建议 |
|---|---|---|---|---|
| 1. 评分预测质量 | RMSE | 0.0027 | 极优秀 | 预测精度极高,但需警惕过拟合。 |
| MAE | 0.0004 | 极优秀 | ||
| R² | 0.9997 | 极优秀 | ||
| 皮尔逊相关系数 | 0.9999 | 极优秀 | ||
| 2. 系统覆盖率 | 覆盖率 | 0.0581 | 极差 | 推荐物品范围过窄,无法帮助用户发现更多内容。亟待改进。 |
| 3. 马太效应 | 所有物品基尼系数 | 0.1352 | 分布平等 | 系统有效避免了“富者愈富”效应,促进了公平性。 |
| 推荐物品基尼系数 | 0.0000 | 绝对公平 | ||
| 差异 | -0.1352 | 效应良好 | ||
| 4. Top-K 推荐质量 | Top-5 | Top-10 | Top-15 | Top-20 |
| 精确率 | 1.0000 | 1.0000 | 1.0000 | |
| 召回率 | 0.0093 | 0.0186 | 0.0280 | |
| F1-Score | 0.0185 | 0.0366 | 0.0544 | |
| NDCG | 0.9999 | 0.9999 | 0.9999 | |
| 多样性 | 0.1275 | 0.1101 | 0.0828 | |
| 新颖性 | 0.0000 | 0.0000 | 0.0000 |
核心结论与行动建议摘要
| 维度 | 结论 | 高优先级行动 |
|---|---|---|
| 准确性 | 过度优化:预测和排序精度极高,但可能已过拟合,牺牲了其他重要指标。 | 1.首要目标:提升覆盖率与召回率。引入长尾物品、调整算法策略(如降低推荐阈值,加入探索机制)。 |
| 覆盖率/召回率 | 严重短板:系统只触及了用户兴趣和物品库的冰山一角。 | 2.核心优化:增强多样性与新颖性。在推荐目标中加入多样性约束,实施“探索-利用”平衡策略。 |
| 多样性/新颖性 | 严重不足:推荐结果同质化严重,无法带来探索的乐趣。 | 3.模型复查:检查模型是否过拟合,确保其在更广的物品范围内仍能保持良好的泛化能力。 |
| 公平性 | 表现优异:系统推荐分布公平,无马太效应。 |
八、系统功能实施
用户端(移动端 Android APP)功能设计
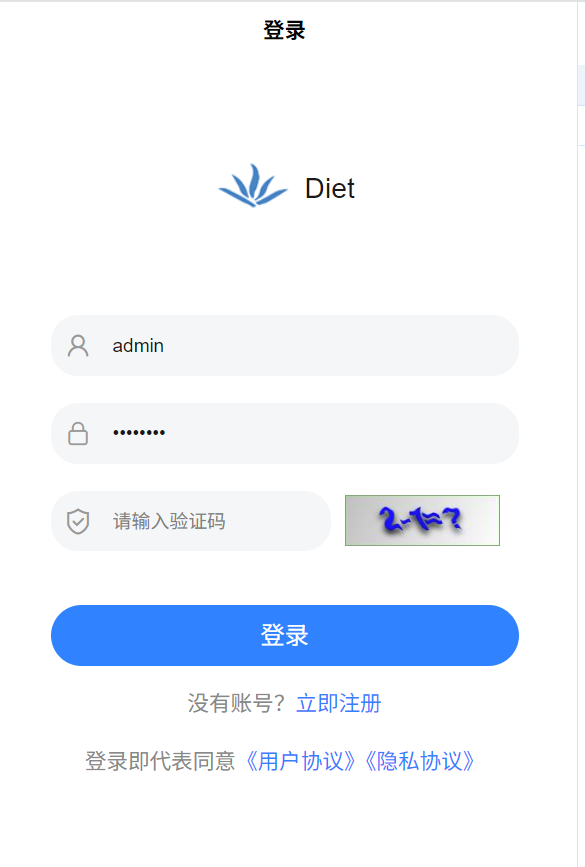
1. 身份验证模块
负责用户账号的创建与安全校验,解决“用户如何合法进入系统”的问题,功能细节如下:
- 注册:用户需按格式输入姓名、手机号、性别、密码(如密码长度 ≥6 位),通过阿里云短信 API 获取 4 位验证码完成注册;信息格式不符(如手机号位数错误、两次密码不一致)时弹窗提示错误。
- 登录:支持“手机号/用户名 + 密码”登录,输入错误(如密码错误、账号不存在)时提示具体原因;登录成功后记录“上一次登录时间”并跳转至系统首页。
- 找回密码:通过注册手机号接收验证码,验证通过后可重置密码(需两次输入一致的新密码),重置成功后同步更新数据库并跳转登录页。

2. 信息管理模块
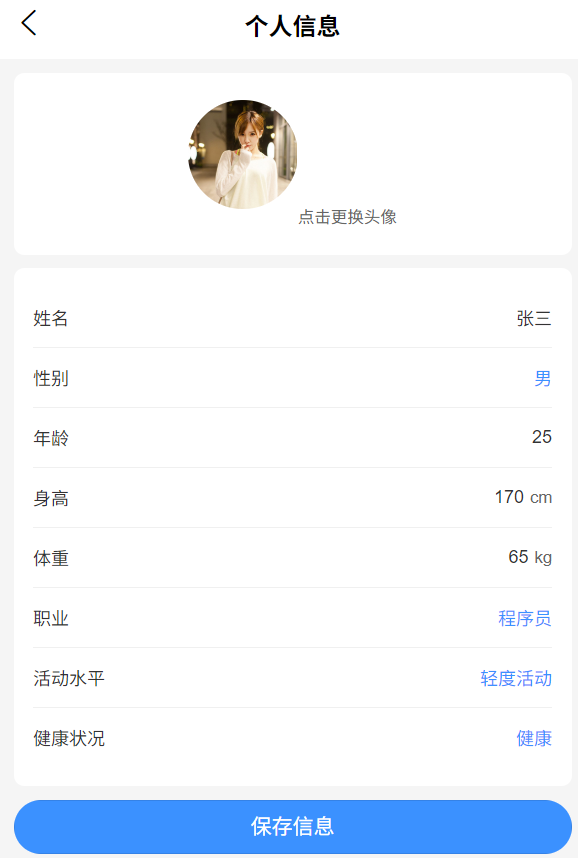
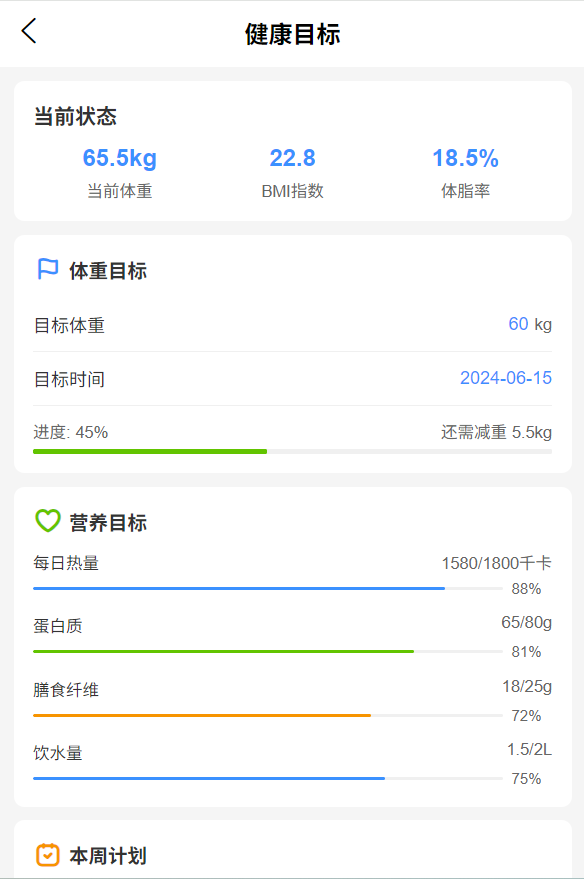
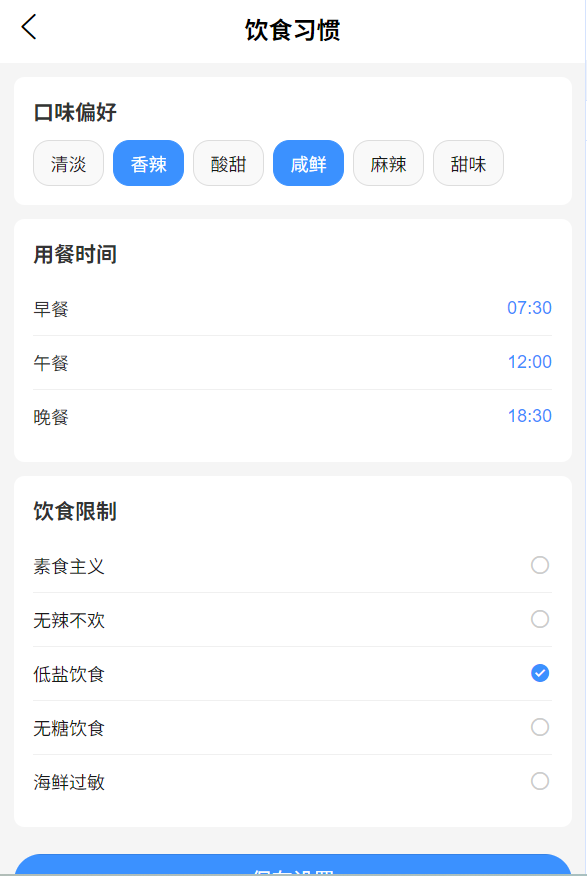
负责用户个人信息与行为记录的管理,为“口味偏好预测”与“营养规划”提供数据支撑,功能如下:
个人信息管理:
- 查看:展示用户基础信息(姓名、性别、年龄、身高、体重、职业、身体活动水平(轻/中/重)、健康状况(无特殊疾病)、注册时间);
- 修改:支持编辑身高、体重、职业、身体活动水平等信息,修改后实时同步至数据库(如将“轻活动水平”改为“中活动水平”)。
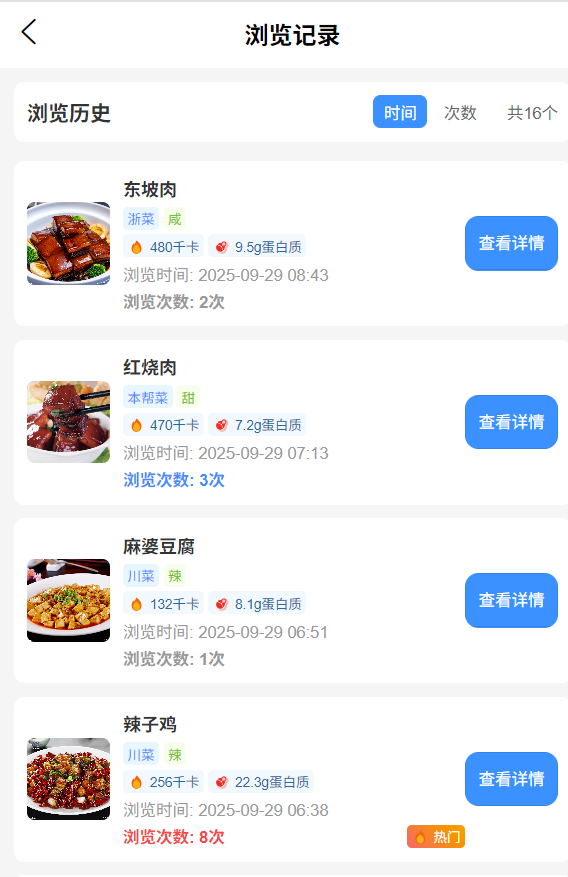
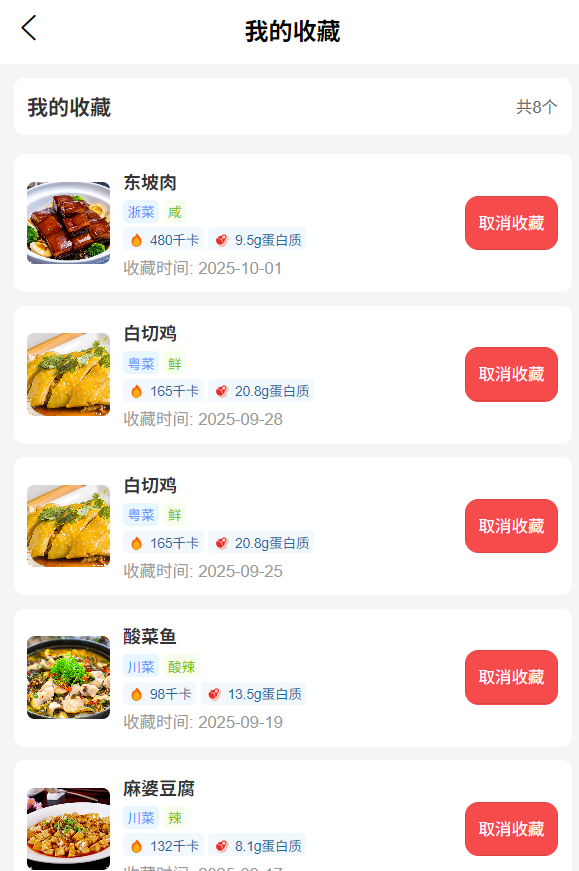
行为记录查询:(保留:我的喜欢)
- 我的喜爱:展示用户收藏的高评分菜品,支持“取消收藏”操作,收藏状态实时同步至数据库。
3. 饮食推荐模块(核心功能)
是用户端核心模块,通过“口味偏好预测 + 营养均衡计算”解决“推荐什么菜”“吃多少”的问题,分两大子功能:
(1)菜品推荐子功能(基于改进协同过滤 UPICF)
核心逻辑为“通过用户历史评分预测潜在偏好,生成精准推荐列表”,具体功能:
用户口味偏好建模:
- 构建用户-菜品评分矩阵、菜品属性矩阵(含菜品的食材、口味、功效、烹饪方式等属性);
- 基于 TF-IDF 思想计算用户对菜品属性的兴趣权重(如用户频繁评分“香辣”口味菜品,则“香辣”属性权重升高),引入**时间权重函数(参考艾宾浩斯遗忘曲线)修正早期评分的影响(近期评分权重更高);**
- 填充稀疏矩阵:对用户未评分的菜品,按“菜品属性匹配度”计算填充值(如用户未评过分的“鱼香肉丝”与已评分的“宫保鸡丁”属性相似,则用“宫保鸡丁”评分均值填充)。
用户相似度计算:
- 在传统修正余弦相似度基础上,引入**用户影响因子(修正用户评分差异的影响)、菜品影响因子(修正菜品本身质量的影响),计算目标用户的近邻用户集(取相似度最高的前 K 个用户,K 最优值为 70)。**
推荐列表生成:
- 基于近邻用户的评分,通过 UPICF 算法计算目标用户对未评分菜品的预测评分;
- 排除用户近 3 日已食用的菜品,按预测评分降序生成 TOP-N 推荐列表(如 TOP10),列表展示菜品名称、评分、收藏数、核心功效(如“减肥瘦身”“降血压”),点击可查看详情。
冷启动处理:若用户无历史评分(新用户),则默认推荐系统内“收藏量 TOP10”的热门菜品,初步建立用户画像;用户产生评分后,自动切换为 UPICF 推荐逻辑。
(2)营养规划子功能(基于 MOPSO 算法)
核心逻辑为“根据用户营养需求,计算菜品中食材的适宜食用量”,具体功能:
用户营养需求确定:
- 根据用户年龄、性别、身体活动水平,查询《中国居民膳食营养素参考摄入量》,确定每餐(早/午/晚)的核心营养元素参考值——包含能量(千卡)、蛋白质(克)、脂肪(克)、碳水化合物(克)(如 24 岁女性轻活动水平,午餐能量参考值为 720.57 千卡,蛋白质 27 克、脂肪 20 克、碳水化合物 108.1 克);
- 按“三餐能量摄入比例 3:4:3”拆分每日营养需求(如每日需 2000 千卡,则早餐 600 千卡、午餐 800 千卡、晚餐 600 千卡)。
食材食用量计算:
- 用户从推荐列表中选择菜品后,系统自动解析菜品所含核心食材(如“木耳炒肉”含黑木耳、猪肉,“西红柿炒蛋”含西红柿、鸡蛋);
- 调用 MOPSO 算法,结合食材营养元素含量(来源于《中国食物成分表》,如 100 克猪肉含 395 千卡能量、13.2 克蛋白质、37.0 克脂肪),计算食材食用量,确保营养元素摄入量在“推荐膳食营养素摄入量(RNI)~可耐受最高摄入量(UL)”范围内;
- 输出 3 套可选食用量方案,每套方案展示“食材名称、推荐量(克)、实际营养元素含量、与参考值的偏差率”(实验验证偏差率 ≤8%,符合健康标准)。
(3)混合推荐模型:
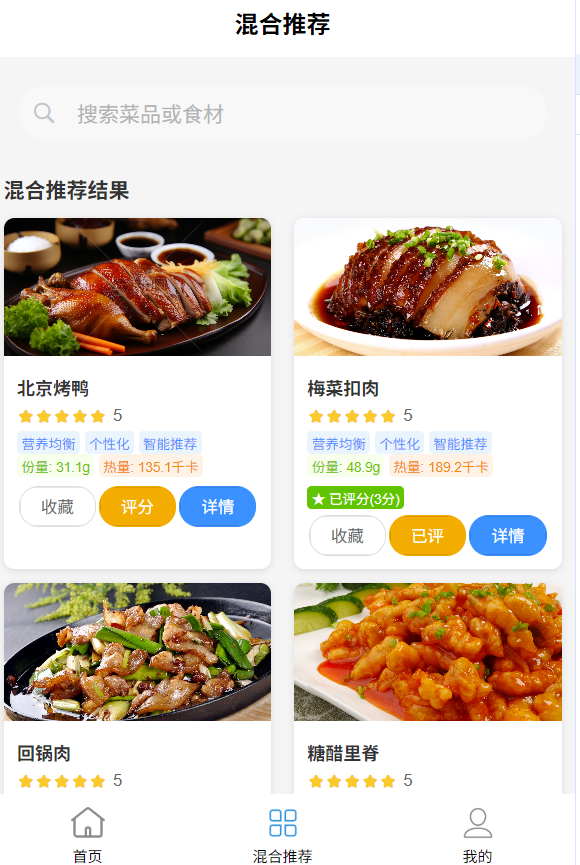

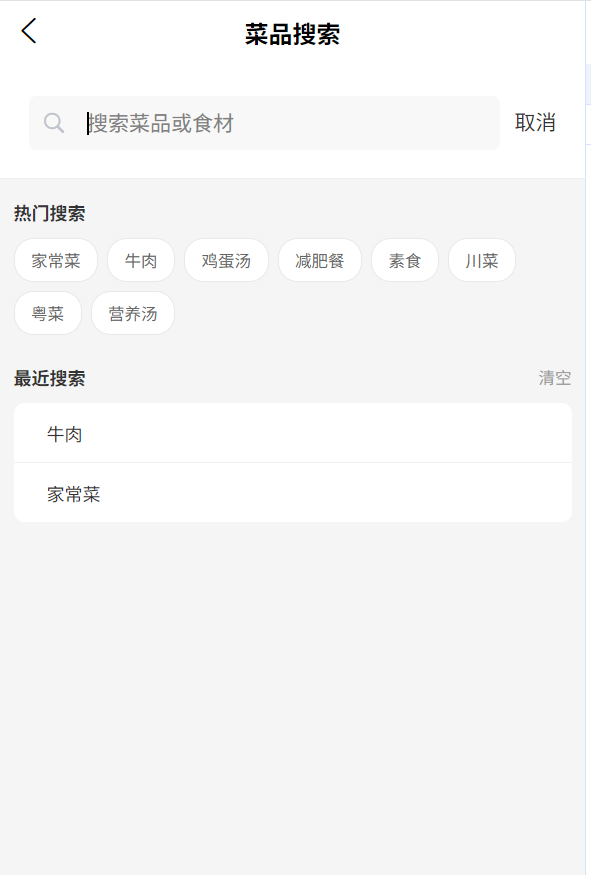
4. 菜品搜索模块
满足用户主动查找菜品的需求,提供高效检索功能,细节如下:
模糊查询:用户输入菜品名称/食材关键词(如“芹菜”“红烧肉”),系统通过正则表达式匹配结果,返回含关键词的所有菜品(如输入“芹菜”,返回“芹菜鸡丝”“芹菜炒香菇”“虾米炒芹菜”);
快捷搜索:
- 热门搜索:展示近一周用户搜索量 TOP8 的词条(如“家常菜”“牛肉”“鸡蛋汤”),点击词条可快速填充搜索框并执行查询;
- 近期搜索:按时间倒序展示用户历史搜索记录,支持“清空历史”操作;
结果交互:搜索结果列表展示菜品名称、评分、核心食材,点击菜品可进入详情页(查看做法、功效、用户评价)。
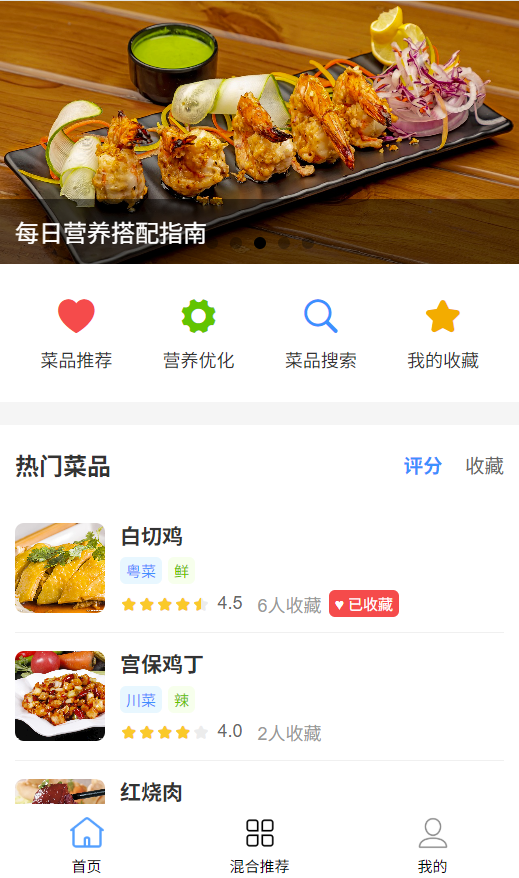
5. 基础辅助模块
提供基础交互与信息展示功能,提升用户体验:
- 营养知识展示:首页顶部设置轮播图,展示营养常识(如“蛋白质的主要来源”“碳水化合物的作用”),点击图片可进入详情页查看完整内容;
- 热门菜品列表:首页展示近一周点击量 TOP10 的热门菜品,支持按“评分(从高到低)”“收藏数(从多到少)”筛选排序,点击菜品可直接加入“待选菜品”用于营养规划。
管理员端(后台 Web 端)功能设计
面向系统管理员,核心目标是“数据管理 + 统计分析 + 反馈处理”,基于 Vue+SpringBoot+Mybatis 实现,包含 3 大核心模块:
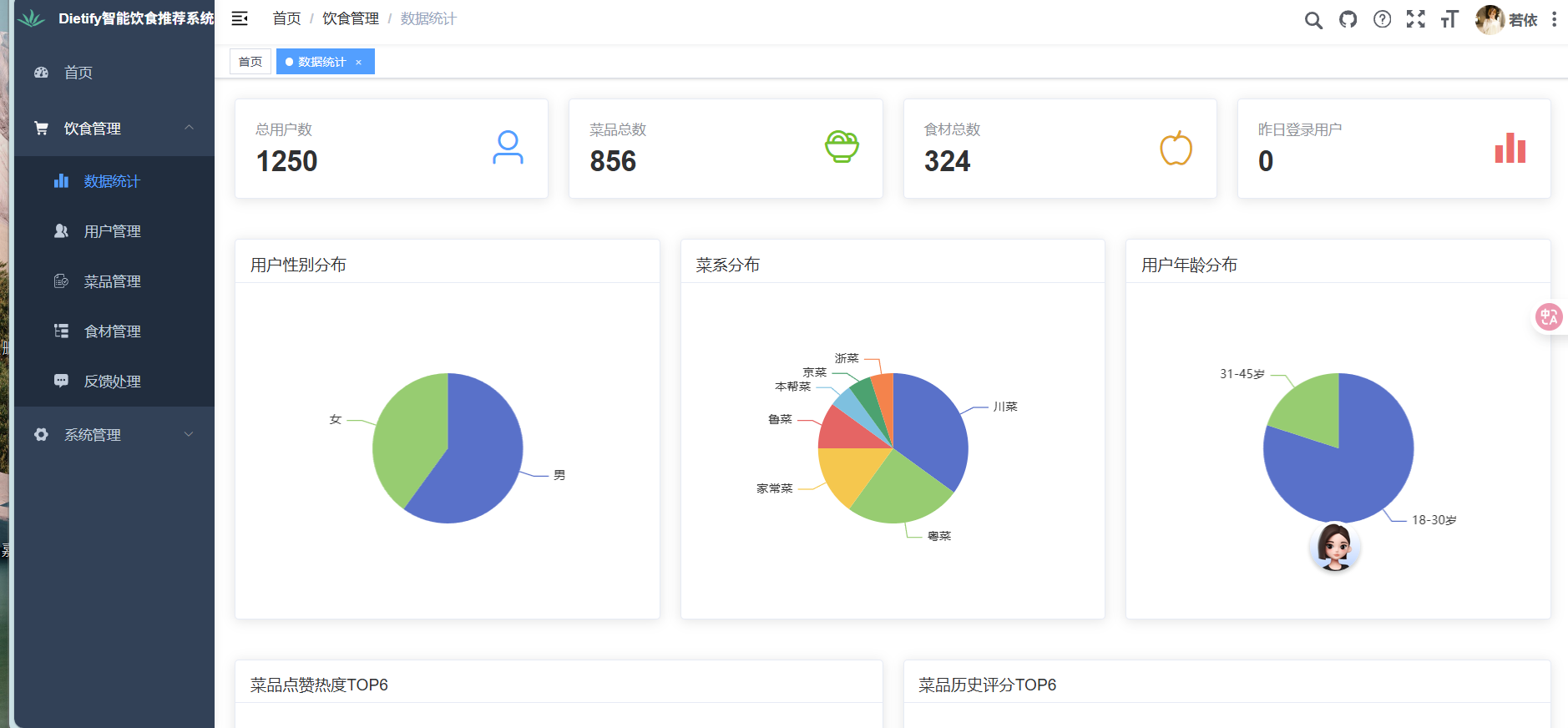
1. 数据统计模块
提供系统运行数据的可视化展示,辅助管理员掌握系统状态,功能如下:
- 核心指标概览:首页展示实时统计数值,包括“总用户数”“菜品总数”“食材总数”“昨日登录用户数”;
- 可视化分析:
- 饼图:展示“菜系分布”(如家常菜占比 40.85%、川菜占比 25%)、“用户性别分布”(如男性 52%、女性 48%)、“用户年龄段分布”(如 40 岁 60%、41~60 岁 25%);
- 柱状图:展示“菜品点赞热度TOP6”“菜品历史评分 TOP6”,鼠标悬浮图表可查看具体数值(如“手撕包菜”评分 94.0 分、收藏 17 次)。
2. 数据管理模块
负责系统核心数据的增删改查,确保数据准确性与完整性,分 3 个子模块:
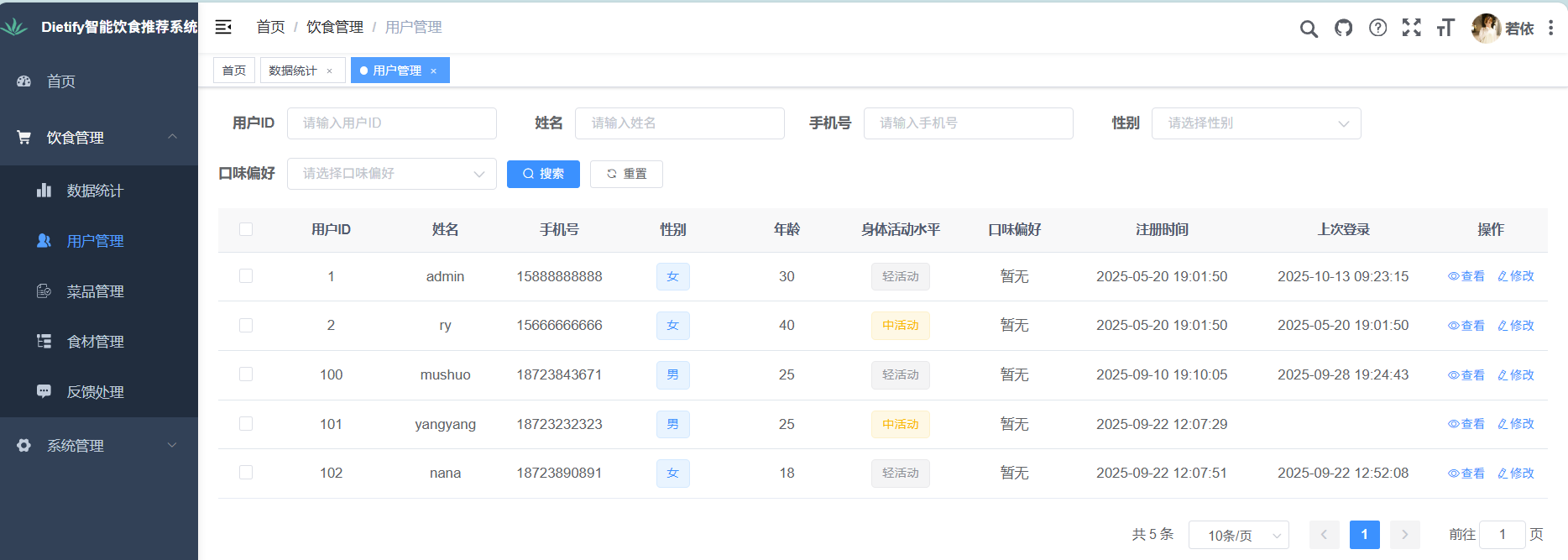
(1)用户信息管理
- 数据查看:按分页展示所有用户的基础信息(用户 ID、姓名、手机号、性别、年龄、身体活动水平、注册时间、上一次登录时间)与行为标签(如“常浏览家常菜”“偏好清淡口味”);
- 操作功能:
- 添加用户:管理员可手动录入用户信息(如为社区特定人群创建账号),录入后同步至用户信息表;
- 编辑用户:支持修改用户“身体活动水平”“健康状况”等信息(如将“无疾病”改为“轻度高血压”,但需备注修改原因);
- 删除用户:支持单个/批量删除无效账号(如长期未登录(超过 6 个月)的账号),删除前需二次确认;
- 模糊查询:通过“用户 ID、姓名、手机号”关键词筛选用户,快速定位目标账号。
(2)菜品/食材信息管理
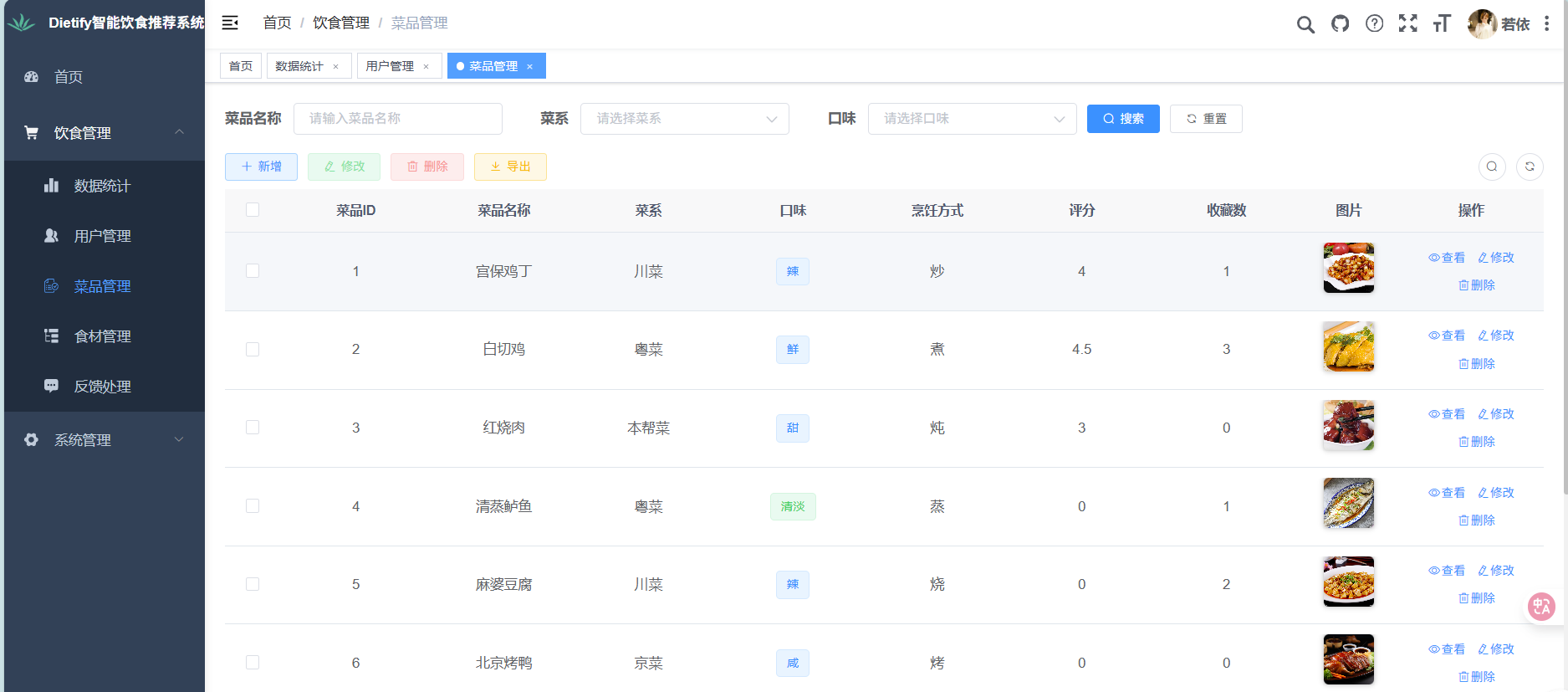
菜品管理:
- 数据查看:展示菜品详情**(菜品 ID、名称、类别、功效、食材、烹饪方式、口味、制作方法、评分、收藏数、图片 URL);**
- 操作功能:添加菜品(录入新菜品信息,上传图片并填写 URL)、编辑菜品(修改口味、做法等内容,如将“微辣”改为“中辣”)、删除菜品(清理数据缺失/低评分(≤30 分)的菜品);支持按“菜系”“评分”“收藏数”筛选菜品。
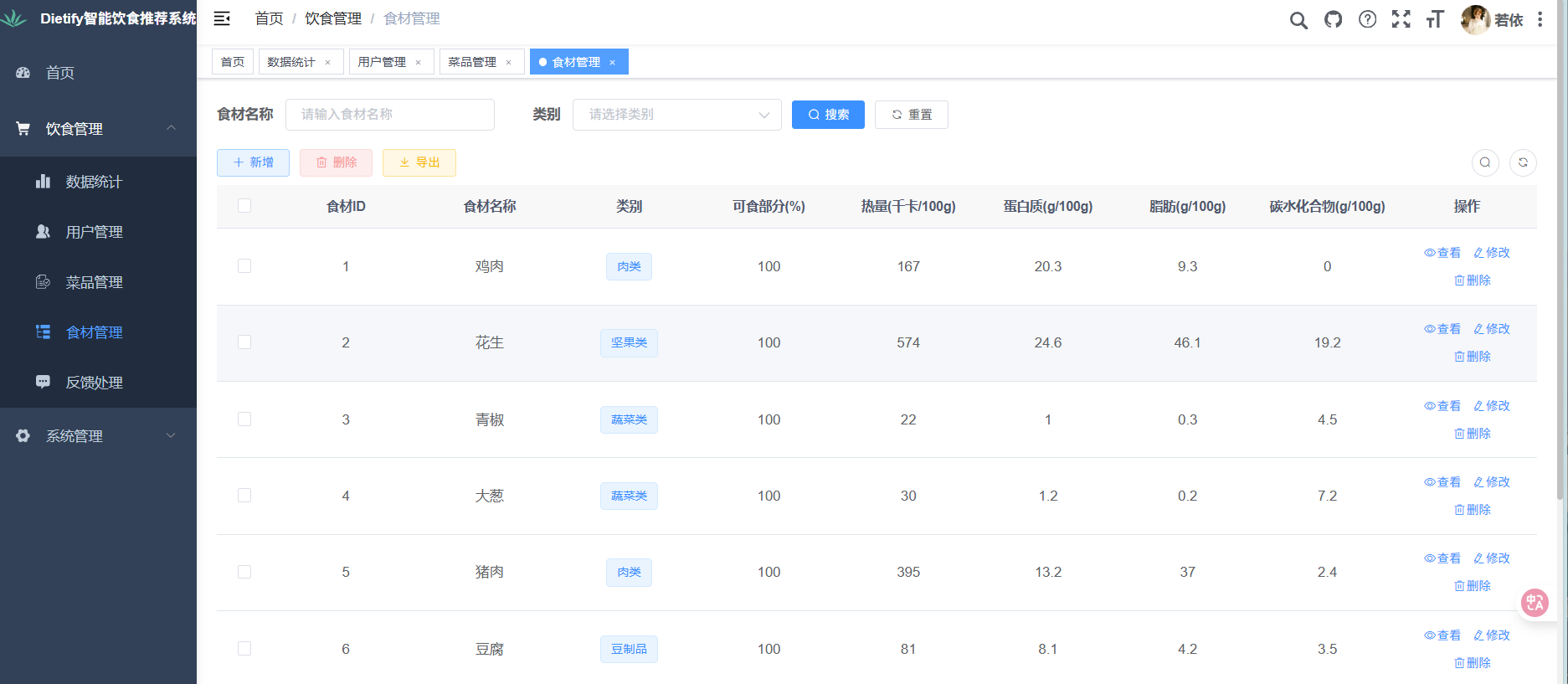
食材管理:
- 数据查看:展示食材营养数据(食材 ID、名称、类别(如谷物类、豆类)、可食部分(%)、热量(千卡/100 克)、蛋白质(克/100 克)、脂肪(克/100 克)、碳水化合物(克/100 克));
- 操作功能:添加食材(从《中国食物成分表》补充新食材,如“藜麦”)、编辑食材(修正营养含量数据,如更新“黑豆”的蛋白质含量)、删除食材(清理无效/重复食材)。
九、存在问题
1.数据的使用性。
1 采用了构建用户画像,调查问卷,提取用户对菜品的特征处理,但缺乏用户对菜品的真实使用数据,(如点击、收藏、评分)等相关具体的真实性数据,对系统真实使用性。——数据来源策略 1
2.若采用用户对菜品的真实使用数据(模拟用户使用),则用户对菜品的稀疏度、冷启动存在弊端。——数据来源策略 2
2.当前进度,已完成任务书、开题报告、毕业设计,进一步完善毕业论文、模型优化
十、附件资料
附件 1:📎 用户饮食偏好.xlsx
附件 2:📎 菜品.xlsx
附件 3:用户数据增强📎enhanced_user_features_960.csv
附件 4:用户数据增强📎enhanced_user_features_960.csv
附件 5:菜品特征📎enhanced_dish_features.csv
附件 6:用户-菜品交互📎user_dish_interaction.csv